Fortunately, not all ranking factors are created equal — you can maximize your SEO efforts by focusing on a few specific ranking factors. Of course, Google’s algorithm is always changing, and we can’t rely on yesterday’s ranking factors as we step into 2017. These top four ranking factors are based on the most recent studies by SearchMetrics, Backlinko, and my colleagues at SEO PowerSuite.
Read on to discover how to optimize your site for today’s important signals.
1. Content
Content is one of the most important Google ranking factors, according to Andrey Lipattsev, a Search Quality Senior Strategist at Google. This shouldn’t be news — content has been an important ranking factor for a while — but in recent years, we’ve seen a shift away from keyword-focused content towards more relevant content written in natural language. Expect to see more of that as 2017 unfolds.
In fact, the SearchMetrics study cited above found that just 53% of the top 20 queries have keywords in their title tag, and less than 40% of landing pages have keywords in their H1. This number is dropping year-over-year, which “clearly demonstrates that Google evaluates content according to its relevance—and not by the inclusion of individual keywords.”
So what exactly does “relevant” content look like? The short answer is: comprehensive.
Consider the top result when you Google “Golden Retriever”:
DogTime’s article on Golden Retrievers rings in at almost 3,500 words, and it covers everything including breed characteristics, history, personality, health, care, and even rescue groups. The page also includes multiple images, infographics, and embedded videos — it’s everything you could ever want to know about Golden Retrievers on one page.
This supports what Backlinko found: Semantic search is here to stay. Algorithm updates like Hummingbird and RankBrain place intense value on semantic relevance and optimization, meaning that an in-depth examination of one topic in easy-to-understand language will always beat out unreadable keyword-dense drivel.
Backlinko also found that long-form content ranks better than short-form content, probably because it allows articles to consider their subject in more detail. That said, SearchMetrics found that mobile content is usually only 2/3 the length of desktop content, and mobile use is on the rise.
How to optimize:
Content influences a variety of other ranking factors, such as bounce rate and CTR. So for best results, make sure your content is both comprehensive and relevant to your audience — an in-depth examination of flamenco dancing probably won’t do much for your auto-repair business.
I recommend you use content auditing software to:
Find and fix thin content.
Explore fewer topics in greater detail on each page.
Improve your Topical Authority in your niche.
2. Backlinks
Backlinks remain an important Google ranking factor, but over the years, Google has learned to weed out the bad links from the good. More links will still result in a higher score, but only if they’re from a number of diverse and authoritative domains.
The key to a strong link building campaign in 2017 is to create content people crave, and then to promote that content relentlessly. When other industry authorities read and link to your content, Google will read your backlink’s matching anchor text and consider your content more relevant.
When your content earns a lot of these high-quality backlinks, you hit three important ranking signals: number of backlinks, link authority, and link diversity.
Note that one of the main roles of social signals is to win you more high-quality backlinks. SearchMetrics found that ranking position and social signals strongly correlated across all social media channels — though Facebook is still the platform with the highest concentration of user interactions.
How to optimize:
There are many different ways to approach link building, but what they all boil down to is content marketing. Step one: Create high-quality content. Step two: Promote.
If you’re not sure where to start, I recommend reading this article by Anna Crowe on 2016’s important link building strategies. If you’re having trouble coming up with original content, consider using the Skyscraper link building technique: Find someone else’s relevant content with lots of backlinks, improve upon their content with a more detailed article, and then share your content.
I also recommend you use link auditing software to get a better picture of your link profile. Use this software to:
Monitor how many links your content has and the quality of those links.
Reach out to high-quality partners for backlinks.
Eliminate spammy and low-quality links; disavow them if you can’t get them removed.
3. Mobile-First User Experience
One of the biggest changes we saw in 2016 was Google’s shift towards mobile-first indexing. This means that Google’s index will now primarily crawl the mobile version of websites as opposed to the desktop version.
Mobile optimization is an extremely important ranking factor. All of the top 100 most visible domains have mobile-friendly solutions, according to SearchMetrics.
In 2017, it will be more important than ever that your content is responsive on all mobile platforms and identical to the content on your desktop site. Mobile-friendliness is now the norm, and with 85% of all websites now meeting Google’s criteria for being mobile-friendly, it’s time to improve your website even more — think mobile-first, not just mobile-friendly.
A word of warning: according to Google, if you are in the process of building a mobile version of your site, don’t launch it until it’s finished. Releasing a broken or incomplete mobile version of your website might wind up hurting your ranking more than helping; it’s better to keep your website desktop-only until the mobile version is ready.
Page speed is another important ranking factor that ties heavily into a good user experience. Desktop websites should load in 3 seconds or less, while mobile websites should load in 2 seconds or less (according to SearchMetrics, the top-ranked mobile websites are approximately one second quicker than their desktop equivalents).
Use the Structured Data Testing Tool to ensure that the same structured markup exists on both your desktop and your mobile site.
Ensure that your mobile site is accessible to Googlebot using the txt testing tool.
Test your page speed using PageSpeed Insights. If your page is slow, use an auditing tool to find and fix uncompressed content, page errors, and other elements slowing your website down.
4. Other Technical Factors
There are many other technical factors which might play a big role in your website’s rank. These factors include:
Encryption: Backlinko still finds a strong correlation between HTTPS websites and first page Google rankings, and SearchMetrics confirms that 45% of the top websites all use HTTPS encryption (up from 12% in 2015). Google confirmed back in 2014 that websites with a strong HTTPS encryption will rank better than their HTTP counterparts, and, as of 2017, websites that have not switched to HTTPS are now marked as unsafe in Google Chrome.
H1 and H2 Headings: There are more landing pages with an H1 and H2 in the source code this year. SearchMetrics found a strong correlation between the use of at least one H2 and a higher rank.
Anchor text: Exact-match anchor text still has a strong influence on rankings, but you risk a Penguin penalty if your links appear unnatural or spammy. Make sure your backlink anchor text is diverse and organic.
Interstitials: In keeping with Google’s emphasis on mobile-first optimization, as of 10 January 2017, they’re cracking down on intrusive interstitial pop-ups. That means any page with an ad or CTA that covers the main content or whisks users to a new page upon clicking might suffer a penalty. Exceptions to this include login dialogs, small banners that are easy to dismiss, and legally-required interstitials (e.g. age verification).
How to optimize:
Switch to HTTPS encryption.
Make use of H2 headings, especially if the top URLS in your niche don’t.
Ensure that your anchor text is diverse and semantically relevant.
Remove all intrusive interstitials from your mobile website.
Original Source: https://www.searchenginejournal.com/2017s-four-important-ranking-factors-according-seo-industry-studies/184619/
Get Information About Best SEO Back Link Building Tools & Software and choose what your works for your business model
Link Building
What is link building?
We won’t be discussing how or why link building is done in this article, but you can click on the definition above if you are at a beginner level in terms link building to learn more about it.
Instead, we are going to list the tools we deem as important and which can help you if you plan to run your own campaigns to build links for your websites.
Ahrefs is a toolset for SEO and marketing. You will be able to see a comprehensive backlink profile of your website and also, your competitor’s website. One of the best tools to use if you are running a competitor link building campaign.
Brokenlinkcheck is a free online web-site validator / integrity checker / problem detection tool that can check your web-pages for broken / dead links, validate, find, and report bad hyperlinks.
The Competitor Analysis tool is designed to provide a breakdown of your website’s search friendliness against your competitors based on various SEO metrics.
Linkstant monitors your website for new links and records any new linking URLs that it discovers. It alerts you to these new links within a few seconds.
LinkAssistant SEO Tool is loaded with a wealth of features to entirely transform your link building experience, making it many times faster and child-easy.
Long Tail Pro is the keyword research software used by 70,000+ marketers and SEOs to find the best long tail keyword ideas and quickly analyze the competition
Microsite Masters is a powerful toolset that allows SEOers and Agencies of all kinds to get the most accurate and up to date ranking information for all of your websites and keywords.
Monitors the whole SERPs for your keywords and industry while utilizing our 3rd party integrations, social signals, and A.I. Bots to help you dominate your SEO and ORM campaigns.
Free/Paid
Ideally, before you even sign up for any of these tools, you should already have mapped your campaign.
Are you going to target your competitor’s links?
Or do you want to write a skyscraper post and go from there?
Determine what you need, and then find the tool(s) that will help make those processes more efficient and effective.
Original Source: https://ninjaoutreach.com/link-building-tools/
Website developers are not always quite as savvy as SEO practitioners when it comes to creating websites that perform well in the SEO arena. Even though development requires a set of technical skills, different technical skills are required for SEO. By following a standard checklist, it can be possible to follow Google’s Webmaster guidelines while also getting ahead in the all-important competitive space in SEO. This checklist looks at things like site speed optimization, structured data, HTML improvements, cross-platform compatibility, and other development tasks from a developer’s perspective in the context of SEO.
By examining these items in further detail, we can identify potential roadblocks and bottlenecks most commonly associated with the website development life cycle. This checklist identifies items routinely covered in Google’s webmaster tools, and then some, to ensure that you have all bases covered for a successful website optimization, every time. In addition, this checklist will also cover lesser known but crucial items that are important to tackle during development before they go live on the site.
Is My Google Webmaster Tools Properly Installed? Is Google Analytics (Or Stats Tool of Choice) Installed?
Most websites use Google webmaster tools and Google Analytics as their statistics tracking program of choice. Of course, there are other options. But tracking programs are worthless if they are not configured correctly.
Checklist Item #1: Is My Traffic Tracking Program Installed Correctly?
If your tracking program is not installed properly, it is possible that it will spit back erroneous, incorrect data, or worse, duplicate data showing an increase when there may not even be an increase. At its simplest, make sure that the tracking program tags (if needed) are all only installed once on the page. Multiple installations and erroneous installations can become major headaches later. Google recommends using Google Tag Manager for more complex analytics installations.
Look Into This: Mobile First Development
A mobile-first index coming from Google has long been rumored, and finally, it’s no longer a rumor. In web development, considering a mobile-first approach is always a good idea.
Checklist Item #2: Is Your Site Mobile-Friendly?
Mobile-friendly can mean two different things in the development world.
Does the site adhere to standard development techniques using a responsive CSS stylesheet with media queries? Or…
Does the site utilize a separate mobile subdomain (m.domain.com)? While there is nothing inherently wrong with using a mobile sub-domain, it can make SEO more difficult.
Any time you utilize a sub-domain, you are telling Google, in essence, that it is a second physical web property. Compared to using a sub-folder, which is typically an extension of a site, the sub-domain will be considered a separate web property and can be harder to manage when it comes to certain SEO tasks like link acquisition.
Checklist Item #3: Mobile URL Structures Leading to Duplicate Content
It is this author’s opinion that, with a site using the m.domain.com structure, your site should be developed in such a way that URL structures do not result in being identified as duplicate content.
Duplicate content can arise from using multiple URLs to show the exact same content. When creating a mobile site using a mobile sub-domain, the general best practice is to make sure a rel=canonical tag is used to show the desktop site as the original source of content. This can help prevent duplicate content issues. Please note that Google’s developer guidelines also recommend doing this.
In addition, make sure that URL structures during development don’t get out of hand, especially when setting up a site for https:// (secure hypertext transfer protocol). It is typical development protocol to obtain secure certificates for sites that are using https://, but be careful. If you do not purchase the right secure certificate, you can create crawling problems due to soft 404s. It’s like this: If a page of content is on https://www and https://, this just leads to crawl problems and duplicate content because Google easily gets confused by multiple URLs showing the same content.
To avoid this issue, always purchasing the wild card version of the secure certificate will help make sure that duplicate URLs are not created during development. Otherwise, you will manually have to perform 301 redirects, which can become a nightmare when you’re dealing with a larger site.
Because of the inherent problems developing a site with secure, mobile, and other types of URLs as noted above, it is usually the best idea to get a wildcard secure certificate and develop a site from the ground up using one single style sheet to control your layout across devices. This way, you preserve the content on mobile that Google likes to see, you have the opportunity to reduce calls to the server (greater site speed and less bottlenecks as a result), and you reduce URL structure issues by attacking all of the problem areas at once.
Look Into This: Schema.org Structured Data
Schema.org microdata is becoming more important on websites, and creating sites by coding Schema.org microdata properly is crucial.
Checklist Item #4: Is My Structured Data Coded Properly?
Creating a process where you manually check Schema.org structured data by using Google’s Schema.org validation tool is a good process to have that will help you become a more successful coder. Without this process, you’re flying blind and will be at the mercy of Google’s confusion if you don’t have this data correctly executed. While most common errors are uncovered by using Google’s Structured Data Testing Tool, there are other minor errors that can occur that are not. These other errors are crucial to get right, so let’s examine what can happen if you don’t.
Take the following example: You’re creating a website for restaurants and you want to include the website’s restaurant name and location information. After a first pass coding the Schema.org structured data, you realize that you see some strange punctuation and contextual errors within the Schema.org data. For example:
<div itemscope itemtype=”brand”><span name=”organization”>Copyright Company Name, All Rights Reserved</span></div>
<div itemscope itemtype=”brand”> Copyright <span name=”organization”>Company Name </span>, All Rights Reserved</div>
Notice in the first example that the copyright declaration is included within all the tags. In the second example, the Company Name is nicely placed between the opening and closing span tags. This second example is what we want.
This is one example of contextual coding errors that can occur when coding Schema.org microdata. These types of errors will not show up in any automatic tool like Google’s webmaster tools, and thus it is necessary to perform a manual check to look for these errors. If the first coding example is used, Google will show the rich snippet as “Copyright Company Name, All Rights Reserved” instead of showing the rich snippet as “Company Name” which is what should happen.
By implementing a thorough checking process before the site ever goes live, as a developer, you can take charge and make sure these types of issues don’t crop up later during the SEO process.
Look Into This: Check Your Robots.txt File
Sometimes, during development, it may be necessary to completely block access to the domain before it goes live. Usually, this is done by using the following command in a robots.txt file on the server:
Disallow: /
However, I have run into quite a few instances where this set of code has been completely forgotten. The client calls me, wondering why their site is not performing. Always make sure there isn’t a disallow directive in robots.txt. This will prevent crawling by the search engines and can be a major damper on a website’s performance.
Now, there is a big difference between “Disallow:” and “Disallow: /”. For non-SEO practitioners, these directives can seem confusing.
Disallow: (without the forward slash) means that all search engine spiders and user agents can crawl the site without issue from the site root down.
Disallow: / (with the forward slash) means that everything from the site root down will be fully blocked from search engine indexing access.
Checklist Item #5: Does My Robots.Txt File Have a “Disallow From The Root Directory” Directive?
As you may imagine, the proper removal of this directive is a good checking step to ensure that search engines can access your site properly.
Look Into This: Staging Site Domain Check
As most developers are aware, during the development process a staging site is created for the purpose of testing new code, previous versions of the site, and correcting other issues before it goes live. A common error during the development process is missing a few instances of a staging site domain when preparing the site for its first launch. This check can help eliminate errors like images not loading properly once the site is switched live, 404 errors due to pages referencing the staging subdomain instead of the live site domain and other issues.
Checklist Item #6: Does My Site Contain Instances of Staging Site Sub-domains?
It is possible, through the use of efficient find and replace techniques, to quickly search for and replace any instances of the staging site sub-domain. For example, in your favorite development program, using Ctrl + H on a Windows machine (or cmd + H on a Mac), you can easily use find and replace for finding all instances of the occurrence of the staging site sub-domain (for the sake of our example, let’s use “stage. domain.com”). When the site is switched live, the domain.com will be reflected in full instead of stage.domain.com. But, if a checking process is not implemented, the site could go live with stage.domain.com URLs being referenced everywhere.
Please note: This checking process will likely not be needed if a relative URL is used during development, as opposed to absolute URLs. For those who are not familiar with this, relative URLs drop everything before the first sub-folder in a URL structure, leaving it looking like this: “folder 1/folder 2/page.html”. An absolute URL includes domain.com at the beginning of the URL structure, leaving it looking like this: “domain.com/folder 1/folder 2/page.html”. It is in the case of absolute URL structures where this check is necessary. Depending on your site’s configuration, you may not even need to implement this step.
Look Into This: HTML Errors
Common HTML errors can often lead to poor rendering of the site on various platforms, which in turn can cause issues with user experience and site speed. This can then cause issues with site performance from a rankings perspective. While this is NOT a direct rankings impact, it can be an indirect rankings impact, kind of like when W3C valid code is not used. W3C validity is not required for ranking sites, but it can lead to an indirect increase in rankings because W3C validity can help reduce site speed through better-optimized layouts and coding techniques. Better coding techniques can also help Google understand your site easier.
It is imperative to note here that utilizing a checklist for common errors will not get rid of everything, and may only cause a slight blip in performance increase if other major issues already exist on a site. But, they are worth fixing when you have all of your SEO ducks in a row.
It is also worth noting here that there are two schools of thought when considering HTML issues. One school of thought believes that correct coding is not essential, that the site will perform and do well in Google anyway. Another school of thought believes that correct coding can lead to increased performance including increased performance in the search results. Who is right? It is this author’s opinion that the correct answer is to always validate your coding.
As a born-and-raised developer turned SEO, it has always been my own best practice to perform complete W3C checking and validation on my sites WHEN I have complete and full control over them. Is it always possible to achieve that kind of coding nirvana? I think so. There are situations where this kind of coding ideal is not possible, so it is necessary to judge the situation for yourself, as not everything discussed here will always apply.
Checklist Item #7: Does My Site Contain Major Instances of Coding Errors?
One common coding error is the utilization of polyglot documents or documents that were coded with one document type, but implemented on a new platform with another document type. When I was in law firm SEO, I ran into this often when developers were attempting to cut corners. The general appearance of coding documents in this manner resulted in many coding errors being thrown by the W3C validator, sometimes thousands.
To the inexperienced, it seems as if you would need to change every HTML tag or other instance of coding in order to comply with W3C standards. Not at all. It ended up being the case of pure ‘copy and paste’ of the code. In most instances where budgets, project scoping, and other issues interfered with development times, it could be impossible to implement the right fix, which is to make sure all coding adheres to the chosen document type.
The simple solution, especially on large sites where large budgets, inter-departmental cooperation, and third parties are involved, would be to simply change the DOCTYPE line to be the right DOCTYPE the document was coded in.
Checklist Item #8: Does My Site Contain an Efficient Code Layout?
How code is laid out is extremely important, as explained by Michael King, Founder and Managing Director of iPullRank. Code layout can impact rendering times, overall site speed, and eventually the final performance of the site. From a server perspective, this is a crucial step to get right.
From the client-side perspective, this can also impact load times. When considering client-side coding, let’s time travel a bit. Back in the olden days of 1998, it was not uncommon to find code layouts with 2400 rows and 2400 columns in table non-CSS designs. Here, in 2017, it is also not uncommon to find bloated code layouts with 50 rows and 50 columns created entirely in nested DIVs, where the amount of rows and columns is inappropriate and contributes nothing to the overall layout.
Of course, I am exaggerating on the number. By putting a little thought into a layout, it is possible to compress some over-bloated layouts down to three DIVs (and maybe one or two nested DIVs): header, content, and footer. This applies to the client-side. On the back-end from the server side perspective, code layout of everything from PHP to JavaScript, CSS, and HTML, efficient development practice should take into account the minification of code, as well as better coding layouts.
One more issue: Meta tags should also be coded according to DOCTYPE. If the W3C validator throws errors due to meta tags, it is most likely being caused by self-closing meta tags being used in a DOCTYPE that does not provide for them. For example: (<meta name=“description” content=“” />) as opposed to <meta name=“description” content=“”>). The former is an instance of a self-closing meta tag, which can be required in XHTML documents. In standard HTML 5, it is not required to use it. Make sure you know the rules and how to implement them when using differing DOCTYPEs. Otherwise, these errors can cause issues.
Look Into This: Image Issues
Images are used in web design to convey mood, tell a story, and make things look cool. However, they can impede the user experience when they become too large. Now, more than ever, with Google’s mobile index looming, it is important to consider image size when it comes to enhancing site speed on mobile. While it has always been a development best practice, not everyone in web development implements best-practice techniques.
Ok, so let’s time travel again. In the olden days of 1998, it was commonplace to make sure that pages never exceeded 35 kB in size. According to HTTP Archive, most web pages now don’t exceed 14 kB in size for the HTML files (not including images). Most web pages now don’t exceed 648 kB as of 12/15/2016, which includes all potential elements (like scripts, fonts, video, images, etc.). What is the best page size to target when developing a site? The smallest size possible given what you are developing for. Any improvement towards faster site speed can help improve your site performance overall.
Checklist Item #9: Are Images Causing Unnecessary Bottlenecks?
It is this author’s opinion that it should be standard for developers to optimize images. In my experience, I’ve found that many developers are not utilizing image compression techniques. For example, it is possible to take an image, compress it down to manageable file size in Photoshop while maintaining quality and physical dimension size. This is usually done on photos by adjusting the JPG settings when exporting an image for the web.
Different Development Platforms: Are Images Unnecessarily Large When They Don’t Have to Be?
This not only takes into account physical download size but also the image pixel dimensions in general (these are not always mutually exclusive, depending on the platform you use). I have found WordPress developers to be a major offender of this particular checklist item. Images will be uploaded to WordPress and resized without much regard for the physical download size of the image.
This can result in a 20 x 20 image on WordPress being 2 MB in size if you are not careful. To make sure this does not happen, always open the image in Photoshop (or whatever image compression program you use) to resize it and compress it properly using lossless compression. Doing this and carefully keeping watch on the final image download size within WordPress will help make sure that unintentional file size increases will not negatively impact your site speed.
Look Into This: Search Plug-Ins, Other Plug-Ins
Whenever you develop a website, especially on platforms like WordPress, issues can crop up even when the developer is not at fault. Search plug-ins can cause especially harmful, irreparable damage to a website’s reputation if they are not caught early. One such instance can be if a search plug-in creates multiple pages for every single search result typed into the search plug-in. When this happens, not only do you get many blank pages without content, you can also run up the bandwidth bill from your website hosting provider.
Checklist Item #10: Are Any Rogue Plug-Ins Causing Major Issues With SEO?
Other rogue plug-ins can cause major SEO issues especially when they insert things like links into the footers of your pages automatically (site-wide footer links for linking’s sake is against Google’s Webmaster Guidelines: “Widely distributed links in the footers or templates of various sites”), and other issues.
Look Into This: Site Speed and Server Configurations
Utilizing much of the advice in this checklist will help get you to a good spot when it comes to the best options for site speed. There are, however, other issues to consider when server configurations and site speed come into play. Some bottlenecks can be caused by server issues, but it will be up to you to identify and figure out what bottlenecks are being caused by your server. Some common bottlenecks include the following, which are all fairly easy fixes.
First, begin by checking your site speed using Google’s Page Speed Testing tool. They have moved most of their page speed and other insights into their Mobile-Friendly Test Tool. In addition, I recommend also using the site test tool webpagetest.org.
Checklist Item #11: Is Your Server Using GZip Compression?
GZip compression on a server lets the server compress files in such a way that results in faster transfers over a network. It is generally standard on most servers built today, but can sometimes be an issue on some servers. If you don’t know, it is likely already enabled on your host. You can check this by running a test on webpagetest.org.
Checklist Item #12: Server Time to First Byte Loaded
Is the first byte to load taking longer than the rest of your website to load? If so, this could be a bottleneck that can help you squeeze out every last bit of performance during the website development stage. This first-byte time measures the “time from when the user started navigating to the page until the first bit of the server response arrived.” When there’s trouble in paradise on this metric, this can usually mean a server configuration issue that can usually be fixed by your server technician.
If following all the optimization items discussed in this checklist doesn’t work and you have found yourself having a severely long time to first-byte loaded issue, it’s a good idea to check with your server technician. This should help resolve any outstanding issues presented by this problem.
Final Parting Thoughts
Developing websites can be a fun, exciting endeavor. But they can also be a challenging affair wrought with issues that can plague a website’s SEO performance for years to come if you are not careful. Performing an in-depth website audit on an existing site could be the answer you need if you want to solve your website problems.
Otherwise, when developing your website, following the steps in this guide will help you get your site to a great place from an SEO perspective. In the coming year, a mobile-first development approach with an emphasis on site speed will be an essential development step towards winning an edge in the competitive Google SEO landscape.
Original Source: https://www.searchenginejournal.com/complete-seo-checklist-web-developers/185410/
Google’s Algorithm Update Fred – Part of a Larger Algorithm Picture
There has been a lot of Google algorithm update activity as of late, and it would be nice to get some perspective on what’s been going on, as these algorithms can seriously impact your rankings. Now, as you may well know, Google has said it unleashes and roll-outs thousands of updates a year. However, the algorithm updates that have come out of Google recently seem to be weightier than usual, and it’s important to realize that. So let’s then take a look at the recent updates, including last week’s roll-out that has become widely known as ‘Fred’, to see what these updates have in common. Perhaps we can even speculate as to what Google has in-store for the SEO industry.
Google’s Recent Algorithm Update Roll-outs
To gain insight and perspective on the recent Google updates, it behooves us to first get the raw facts. That is, what updates were rolled-out, when were they released, and what were they all about. Google Algorithm Update Fred
Starting our algorithm update journey with the most recent update, we have Fred. Taking place on March 9th (on desktop), this update seems to have targeted spammy links. Named ‘Fred’ by Barry Schwartz of SERoundtable.com, the algorithm update chatter first began within the annals of the black hat SEO forums, thus indicating that the update related to link quality.
Google algorithm update ‘Fred’ as represented by rank fluctuation levels on the Rank Ranger Rank Risk Index on March 9th
Now then, what friendly neighborhood algorithm, that just went “core” and therefore is no longer heralded in by Google announcements, could possibly be behind a raid of spammy links? I’ll give you a hint… it ends in ‘enguin’ and starts with a ‘P’.
However, as time progressed, and after it appeared that Fred was a one-day powerhouse, the Rank Risk Index caught another spike in rank fluctuations. After three days of ‘calm’ our index (desktop) shot up to a risk level of 78 on March 13th followed by a March 14th risk level of 100.
Google algorithm ‘Fred’ shows the start of a second spike in rank fluctuations on March 13th
Interestingly enough this ‘delayed’ spike is thought not to be a separate update, but a second round of ‘Fred’. More than that, reports have been coming in that the sites hit were content oriented sites that were predisposed to a large volume of ad placement (think sites pushing content just so they can place ads and make a quick dollar or two). It is speculated that the lull in rank fluctuations was a result of sites being restored after rectifying their overindulgence in ads (i.e. after scaling their ads back some).
What then of the reviving of ‘Fred’ and the second round of fluctuations? I speculate that Google turned the juice up after missing sites it had intended on demoting. In other words, after giving sites the chance to make a correction, Google went back to work by demoting additional sites.
As such, my final diagnosis is that ‘Fred’ is a mix of Penguin and Panda. Again, this is my own speculation as Google has confirmed nothing thus far. However, I don’t see the initial report of the update being related to link quality as being inaccurate. In fact, sites with poor content usually also have poor linking practices, and are also usually overloaded with ads. It’s almost as if Google tracked these sites down using Penguin and Panda, and then demoted them on the basis of a third criteria, advertising overindulgence (as opposed to poor content and spammy links per se).
February’s Significant Algorithm Update Roll-out
Almost exactly a month before ‘Fred’ was released, Google rolled-out another major update. Unlike ‘Fred’ the roll-out was a multi-day event that ran from February 7th through the 10th. Like ‘Fred’, there was some early chatter that the update was link quality related. However, though no official Google statement was released, SearchEngineLand theorized that the update was related to Panda, yet another part of Google’s core algorithm.
An Early February Algorithm Tweak
Of the three changes to Google’s algorithm, this one was seemingly the least impactful. In this early February tweak, our Rank Risk Index, while showing increased rank fluctuations, did not present overly-alarming fluctuation levels. That being said, the fluctuation levels on the index were elevated, and the industry did recognize that something had shifted over at Google. Again speculating as to the nature of the algorithm change, SearchEngineLand reported that the Penguin algorithm may have been altered, changing how it goes about discounting links thought to be spam.
The Rank Risk Index shows both a moderate and significant spike in rank fluctuations during February
What Google’s Recent Algorithm Updates Indicate
Obviously keeping tabs on the updates Google releases is important, it could explain why your rankings have suddenly shifted. However, it would be quite helpful looking to the future if we could understand, or simply get a glimpse into a sort of algorithm update pattern. If there is a trend within the recent updates, that could help us maneuver our SEO going forward.
The Timing of the Updates
Firstly, it’s important to note that all of these updates have occurred in 2017. It’s also important to note, that the listed algorithm activity represents all of the more notable Google algorithm activity in 2017. In other words, the algorithm changes listed here represent Google’s more substantial roll-outs since the new year started and thus it is safe to assume (in my opinion) they thereby represent Google’s focus for the new year, at least a part of it.
Core Algorithm Updates
The second thing to notice with these updates is that should industry speculation hold true, they are all related to parts of Google’s core algorithm. In other words, Google, over the past month or so, has seemingly gone back to basics, particularity those basics that deal with poor content or links to it (i.e. Panda and Penguin). Though they have seemingly taken it one step further (rather logically actually) by demoting sites based on criteria that straddles both algorithms, over-advertising.
Combining this revelation with my previous point regarding Google’s timing, it would seem that Google is intent on demoting sites that either harbor or facilitate bad content. That the focus, as the year has started, is to significantly shake things up when it comes to poor content and links to such content. As the new year began, Google was quick out of the gate to target sites that employed sub-par content as well as those sites linking to sub-par content. With three updates all related to this topic within the span of a few weeks, and all at the start of the new year, this seems to be a safe pattern to bet on.
Each year, Google changes its search algorithm around 500–600 times. While most of these changes are minor, Google occasionally rolls out a “major” algorithmic update (such as Google Panda and Google Penguin) that affects search results in significant ways.
For search marketers, knowing the dates of these Google updates can help explain changes in rankings and organic website traffic and ultimately improve search engine optimization. Below, we’ve listed the major algorithmic changes that have had the biggest impact on search.
2017 Updates
“Fred” (Unconfirmed) — March 8, 2017
Google rolled out what appeared to be a major update, with reports of widespread impacts across the SEO community. Gary Illyes jokingly referred to is as “Fred”, and the name stuck, but he later made it clear that this was not an official confirmation.
Algorithm changes beginning on February 1st continued for a full week, peaking around February 6th (some reported the 7th). Webmaster chatter and industry case studies suggest these were separate events.
There was a period of heavy algorithm flux starting around February 1st and peaking around February 6th. It is unclear whether this was multiple algorithm updates or a single update with an extended roll-out, but anecdotal evidence suggests at least two updates.
Google started rolling out a penalty to punish aggressive interstitials and pop-ups that might damage the mobile user experience. Google also provided a rare warning of this update five months in advance. MozCast showed high temperatures from January 10-11, but many SEOs reported minimal impact on sites that should have been affected.
Multiple Google trackers showed massive flux around December 14-15, including a rare MozCast temperature of 109°F. Webmaster chatter was heavy as well, but Google did not confirm an update.
MozCast detected a major (106°) spike on November 10th and another on the 18th. Industry chatter was high during both periods, with some suggesting that the second spike was a reversal of the first update. Google has not confirmed either event. Many people reported bad dates in SERPs during the same time period, but it’s unclear whether this was causal or just a coincidence.
The second phase of Penguin 4.0 was the reversal of all previous Penguin penalties. This seemed to happen after the new code rolled out, and may have taken as long as two weeks. Post-Penguin activity had one final peak on October 6th (116°), but it is unclear whether this was Penguin or a new update. Algorithm temperatures finally started to drop after October 6th.
Penguin 4.0, Phase 1 — September 27, 2016
The first phase of Penguin 4.0, which probably launched around September 22-23, was the rollout of the new, “gentler” Penguin algorithm, which devalues bad links instead of penalizing sites. The exact timeline is unconfirmed, but we believe this rollout took at least a few days to fully update, and may have corresponded to an algorithm temperature spike (113°) on September 27th.
After almost two years of waiting, Google finally announced a major Penguin update. They suggested the new Penguin is now real-time and baked into the “core” algorithm. Initial impact assessments were small, but it was later revealed that the Penguin 4.0 rollout was unusually long and multi-phase (see September 27th and October 6th).
MozCast recorded a nearly-record 111° temperature and a 50% drop in SERPs with image (universal/vertical) results. The universal result shake-up opened up an organic position on page 1, causing substantial ranking shifts, but it’s likely that this was part of a much larger update.
While unconfirmed by Google, MozCast recorded extreme temperatures of 108° and a drop in local pack prevalence, and the local SEO community noted a major shake-up in pack results. Data suggests this update (or a simultaneous update) also heavily impacted organic results.
Just more than a year after the original “mobile friendly” update, Google rolled out another ranking signal boost to benefit mobile-friendly sites on mobile search. Since the majority of sites we track are already mobile-friendly, it’s likely the impact of the latest update was small.
MozCast and other Google weather trackers showed a historically rare week-long pattern of algorithm activity, including a 97-degree spike. Google would not confirm this update, and no explanation is currently available.
Google made major changes to AdWords, removing right-column ads entirely and rolling out 4-ad top blocks on many commercial searches. While this was a paid search update, it had significant implications for CTR for both paid and organic results, especially on competitive keywords.
Multiple tracking tools (including MozCast) reported historically-large rankings movement, which Google later confirmed as a “core algo update”. Google officially said that this was not a Penguin update, but details remain sketchy.
Google made a major announcement, revealing that machine learning had been a part of the algorithm for months, contributing to the 3rd most influential ranking factor. *Note: This is an announcement date – we believe the actual launch was closer to spring 2015.
Google announced what was most likely a Panda data refresh, saying that it could take months to fully roll out. The immediate impact was unclear, and there were no clear signs of a major algorithm update.
After many reports of large-scale ranking changes, originally dubbed “Phantom 2”, Google acknowledged a core algorithm change impacting “quality signals”. This update seems to have had a broad impact, but Google didn’t reveal any specifics about the nature of the signals involved.
In a rare move, Google pre-announced an algorithm update, telling us that mobile rankings would differ for mobile-friendly sites starting on April 21st. The impact of this update was, in the short-term, much smaller than expected, and our data showed that algorithm flux peaked on April 22nd.
Multiple SERP-trackers and many webmasters reported major flux in Google SERPs. Speculation ranged from an e-commerce focused update to a mobile usability update. Google did not officially confirm an update.
Google’s major local algorithm update, dubbed “Pigeon”, expanded to the United Kingdom, Canada, and Australia. The original update hit the United States in July 2014. The update was confirmed on the 22nd but may have rolled out as early as the 19th.
A Google representative said that Penguin had shifted to continuous updates, moving away from infrequent, major updates. While the exact timeline was unclear, this claim seemed to fit ongoing flux after Penguin 3.0 (including unconfirmed claims of a Penguin 3.1).
More than two years after the original DMCA/”Pirate” update, Google launched another update to combat software and digital media piracy. This update was highly targeted, causing dramatic drops in ranking to a relatively small group of sites.
More than a year after the previous Penguin update (2.1), Google launched a Penguin refresh. This update appeared to be smaller than expected (<1% of US/English queries affected) and was probably data-only (not a new Penguin algorithm). The timing of the update was unclear, especially internationally, and Google claimed it was spread out over “weeks”.
Google made what looked like a display change to News-box results, but later announced that they had expanded news links to a much larger set of potential sites. The presence of news results in SERPs also spiked, and major news sites reported substantial traffic changes.
Google announced a significant Panda update, which included an algorithmic component. They estimated the impact at 3-5% of queries affected. Given the “slow rollout,” the exact timing was unclear.
Following up on the June 28th drop of authorship photos, Google announced that they would be completely removing authorship markup (and would no longer process it). By the next morning, authorship bylines had disappeared from all SERPs.
After months of speculation, Google announced that they would be giving preference to secure sites, and that adding encryption would provide a “lightweight” rankings boost. They stressed that this boost would start out small, but implied it might increase if the changed proved to be positive.
Google shook the local SEO world with an update that dramatically altered some local results and modified how they handle and interpret location cues. Google claimed that Pigeon created closer ties between the local algorithm and core algorithm(s).
John Mueller made a surprise announcement (on June 25th) that Google would be dropping all authorship photos from SERPs (after heavily promoting authorship as a connection to Google+). The drop was complete around June 28th.
Less than a month after the Payday Loan 2.0 anti-spam update, Google launched another major iteration. Official statements suggested that 2.0 targeted specific sites, while 3.0 targeted spammy queries.
Google confirmed a major Panda update that likely included both an algorithm update and a data refresh. Officially, about 7.5% of English-language queries were affected. While Matt Cutts said it began rolling out on 5/20, our data strongly suggests it started earlier.
Just prior to Panda 4.0, Google updated it’s “payday loan” algorithm, which targets especially spammy queries. The exact date of the roll-out was unclear (Google said “this past weekend” on 5/20), and the back-to-back updates made the details difficult to sort out.
Major algorithm flux trackers and webmaster chatter spiked around 3/24-3/25, and some speculated that the new, “softer” Panda update had arrived. Many sites reported ranking changes, but this update was never confirmed by Google.
Google “refreshed” their page layout algorithm, also known as “top heavy”. Originally launched in January 2012, the page layout algorithm penalizes sites with too many ads above the fold.
As predicted by Matt Cutts at Pubcon Las Vegas, authorship mark-up disappeared from roughly 15% of queries over a period of about a month. The fall bottomed out around December 19th, but the numbers remain volatile and have not recovered to earlier highs.
Almost all global flux trackers registered historically high activity. Google would not confirm an update, suggesting that they avoid updates near the holidays. MozCast also registered a rise in some Partial-Match Domains (PMDs), but the patterns were unclear.
Multiple Google trackers picked up unusual activity, which co-occurred with a report of widespread DNS errors in Google Webmaster Tools. Google did not confirm an update, and the cause and nature of this flux was unclear.
After a 4-1/2 month gap, Google launched another Penguin update. Given the 2.1 designation, this was probably a data update (primarily) and not a major change to the Penguin algorithm. The overall impact seemed to be moderate, although some webmasters reported being hit hard.
Announced on September 26th, Google suggested that the “Hummingbird” update rolled out about a month earlier. Our best guess ties it to a MozCast spike on August 20th and many reports of flux from August 20-22. Hummingbird has been compared to Caffeine, and seems to be a core algorithm update that may power changes to semantic search and the Knowledge Graph for months to come.
Google added a new type of news result called “in-depth articles”, dedicated to more evergreen, long-form content. At launch, it included links to three articles, and appeared across about 3% of the searches that MozCast tracks.
Seemingly overnight, queries with Knowledge Graph (KG) entries expanded by more than half (+50.4%) across the MozCast data set, with more than a quarter of all searches showing some kind of KG entry.
Google confirmed a Panda update, but it was unclear whether this was one of the 10-day rolling updates or something new. The implication was that this was algorithmic and may have “softened” some previous Panda penalties.
Google’s Matt Cutts tweeted a reply suggesting a “multi-week” algorithm update between roughly June 12th and “the week after July 4th”. The nature of the update was unclear, but there was massive rankings volatility during that time period, peaking on June 27th (according to MozCast data). It appears that Google may have been testing some changes that were later rolled back.
Google announced a targeted algorithm update to take on niches with notoriously spammy results, specifically mentioning payday loans and porn. The update was announced on June 11th, but Matt Cutts suggested it would roll out over a 1-2 month period.
While not an actual Panda update, Matt Cutts made an important clarification at SMX Advanced, suggesting that Panda was still updating monthly, but each update rolled out over about 10 days. This was not the “everflux” many people had expected after Panda #25.
After months of speculation bordering on hype, the 4th Penguin update (dubbed “2.0” by Google) arrived with only moderate impact. The exact nature of the changes were unclear, but some evidence suggested that Penguin 2.0 was more finely targeted to the page level.
Google released an update to control domain crowding/diversity deep in the SERPs (pages 2+). The timing was unclear, but it seemed to roll out just prior to Penguin 2.0 in the US and possibly the same day internationally.
In the period around May 9th, there were many reports of an algorithm update (also verified by high MozCast activity). The exact nature of this update was unknown, but many sites reported significant traffic loss.
Matt Cutts pre-announced a Panda update at SMX West, and suggested it would be the last update before Panda was integrated into the core algorithm. The exact date was unconfirmed, but MozCast data suggests 3/13-3/14.
Google announced its first official update of 2013, claiming 1.2% of queries affected. This did not seem related to talk of an update around 1/17-18 (which Google did not confirm).
Right before the Christmas holiday, Google rolled out another Panda update. They officially called it a “refresh”, impacting 1.3% of English queries. This was a slightly higher impact than Pandas #21 and #22.
Google added Knowledge Graph functionality to non-English queries, including Spanish, French, German, Portuguese, Japanese, Russian, and Italian. This update was “more than just translation” and added enhanced KG capabilities.
After some mixed signals, Google confirmed the 22nd Panda update, which appears to have been data-only. This came on the heels of a larger, but unnamed update around November 19th.
Google rolled out their 21st Panda update, roughly 5-1/2 weeks after Panda #20. This update was reported to be smaller, officially impacting 1.1% of English queries.
Google announced an update to its original page layout algorithm change back in January, which targeted pages with too many ads above the fold. It’s unclear whether this was an algorithm change or a Panda-style data refresh.
After suggesting the next Penguin update would be major, Google released a minor Penguin data update, impacting “0.3% of queries”. Penguin update numbering was rebooted, similar to Panda – this was the 3rd Penguin release.
Google published their monthly (bi-monthly?) list of search highlights. The 65 updates for August and September included 7-result SERPs, Knowledge Graph expansion, updates to how “page quality” is calculated, and changes to how local results are determined.
Overlapping the EMD update, a fairly major Panda update (algo + data) rolled out, officially affecting 2.4% of queries. As the 3.X series was getting odd, industry sources opted to start naming Panda updates in order (this was the 20th).
Exact-Match Domain (EMD) Update — September 27, 2012
Google announced a change in the way it was handling exact-match domains (EMDs). This led to large-scale devaluation, reducing the presence of EMDs in the MozCast data set by over 10%. Official word is that this change impacted 0.6% of queries (by volume).
Google rolled out another Panda refresh, which appears to have been data-only. Ranking flux was moderate but not on par with a large-scale algorithm update.
Google rolled out yet another Panda data update, but the impact seemed to be fairly small. Since the Panda 3.0 series ran out of numbers at 3.9, the new update was dubbed 3.9.1.
Google made a significant change to the Top 10, limiting it to 7 results for many queries. Our research showed that this change rolled out over a couple of days, finally impacting about 18% of the keywords we tracked.
After a summer hiatus, the June and July Search Quality Highlights were rolled out in one mega-post. Major updates included Panda data and algorithm refreshes, an improved rank-ordering function (?), a ranking boost for “trusted sources”, and changes to site clustering.
Google announced that they would start penalizing sites with repeat copyright violations, probably via DMCA takedown requests. Timing was stated as “starting next week” (8/13?).
A month after Panda 3.8, Google rolled out a new Panda update. Rankings fluctuated for 5-6 days, although no single day was high enough to stand out. Google claimed ~1% of queries were impacted.
In a repeat of March/April, Google sent out a large number of unnatural link warnings via Google Webmaster Tools. In a complete turn-around, they then announced that these new warnings may not actually represent a serious problem.
Google rolled out yet another Panda data update, claiming that less than 1% of queries were affect. Ranking fluctuation data suggested that the impact was substantially higher than previous Panda updates (3.5, 3.6).
Google released their monthly Search Highlights, with 39 updates in May. Major changes included Penguin improvements, better link-scheme detection, changes to title/snippet rewriting, and updates to Google News.
Google rolled out its first targeted data update after the “Penguin” algorithm update. This confirmed that Penguin data was being processed outside of the main search index, much like Panda data.
In a major step toward semantic search, Google started rolling out “Knowledge Graph”, a SERP-integrated display providing supplemental object about certain people, places, and things. Expect to see “knowledge panels” appear on more and more SERPs over time. Also, Danny Sullivan’s favorite Trek is ST:Voyager?!
Google published details of 52 updates in April, including changes that were tied to the “Penguin” update. Other highlights included a 15% larger “base” index, improved pagination handling, and a number of updates to sitelinks.
Barely a week after Panda 3.5, Google rolled out yet another Panda data update. The implications of this update were unclear, and it seemed that the impact was relatively small.
After weeks of speculation about an “Over-optimization penalty”, Google finally rolled out the “Webspam Update”, which was soon after dubbed “Penguin.” Penguin adjusted a number of spam factors, including keyword stuffing, and impacted an estimated 3.1% of English queries.
In the middle of a busy week for the algorthim, Google quietly rolled out a Panda data update. A mix of changes made the impact difficult to measure, but this appears to have been a fairly routine update with minimal impact.
After a number of webmasters reported ranking shuffles, Google confirmed that a data error had caused some domains to be mistakenly treated as parked domains (and thereby devalued). This was not an intentional algorithm change.
Google posted another batch of update highlights, covering 50 changes in March. These included confirmation of Panda 3.4, changes to anchor-text “scoring”, updates to image search, and changes to how queries with local intent are interpreted.
Google announced another Panda update, this time via Twitter as the update was rolling out. Their public statements estimated that Panda 3.4 impacted about 1.6% of search results.
This wasn’t an algorithm update, but Google published a rare peek into a search quality meeting. For anyone interested in the algorithm, the video provides a lot of context to both Google’s process and their priorities. It’s also a chance to see Amit Singhal in action.
As part of their monthly update, Google mentioned code-name “Venice”. This local update appeared to more aggressively localize organic results and more tightly integrate local search data. The exact roll-out date was unclear.
Google published a second set of “search quality highlights” at the end of the month, claiming more than 40 changes in February. Notable changes included multiple image-search updates, multiple freshness updates (including phasing out 2 old bits of the algorithm), and a Panda update.
Google rolled out another post-“flux” Panda update, which appeared to be relatively minor. This came just 3 days after the 1-year anniversary of Panda, an unprecedented lifespan for a named update.
Google released another round of “search quality highlights” (17 in all). Many related to speed, freshness, and spell-checking, but one major announcement was tighter integration of Panda into the main search index.
Google updated their page layout algorithms to devalue sites with too much ad-space above the “fold”. It was previously suspected that a similar factor was in play in Panda. The update had no official name, although it was referenced as “Top Heavy” by some SEOs.
Google confirmed a Panda data update, although suggested that the algorithm hadn’t changed. It was unclear how this fit into the “Panda Flux” scheme of more frequent data updates.
Google announced a radical shift in personalization – aggressively pushing Google+ social data and user profiles into SERPs. Google also added a new, prominent toggle button to shut off personalization.
Google announced 30 changes over the previous month, including image search landing-page quality detection, more relevant site-links, more rich snippets, and related-query improvements. The line between an “algo update” and a “feature” got a bit more blurred.
Google outlined a second set of 10 updates, announcing that these posts would come every month. Updates included related query refinements, parked domain detection, blog search freshness, and image search freshness. The exact dates of each update were not provided.
After Panda 2.5, Google entered a period of “Panda Flux” where updates started to happen more frequently and were relatively minor. Some industry analysts called the 11/18 update 3.1, even though there was no official 3.0. For the purposes of this history, we will discontinue numbering Panda updates except for very high-impact changes.
This one was a bit unusual. In a bid to be more transparent, Matt Cutts released a post with 10 recent algorithm updates. It’s not clear what the timeline was, and most were small updates, but it did signal a shift in how Google communicates algorithm changes.
Google announced that an algorithm change rewarding freshness would impact up to 35% of queries (almost 3X the publicly stated impact of Panda 1.0). This update primarly affected time-sensitive results, but signalled a much stronger focus on recent content.
Google announced they would be encrypting search queries, for privacy reasons. Unfortunately, this disrupted organic keyword referral data, returning “(not provided)” for some organic traffic. This number increased in the weeks following the launch.
Matt Cutts tweeted: “expect some Panda-related flux in the next few weeks” and gave a figure of “~2%”. Other minor Panda updates occurred on 10/3, 10/13, and 11/18.
After more than month, Google rolled out another Panda update. Specific details of what changed were unclear, but some sites reported large-scale losses.
This wasn’t an update, but it was an amazing revelation. Google CEO Eric Schmidt told Congress that Google made 516 updates in 2010. The real shocker? They tested over 13,000 updates.
To help fix crawl and duplication problems created by pagination, Google introduced the rel=”next” and rel=”prev” link attributes. Google also announced that they had improved automatic consolidation and canonicalization for “View All” pages.
After experimenting for a while, Google officially rolled out expanded site-links, most often for brand queries. At first, these were 12-packs, but Google appeared to limit the expanded site-links to 6 shortly after the roll-out.
Google rolled Panda out internationally, both for English-language queries globally and non-English queries except for Chinese, Japanese, and Korean. Google reported that this impacted 6-9% of queries in affected countries.
Webmaster chatter suggested that Google rolled out yet another update. It was unclear whether new factors were introduced, or this was simply an update to the Panda data and ranking factors.
After a number of social media failures, Google launched a serious attack on Facebook with Google+. Google+ revolved around circles for sharing content, and was tightly integrated into products like Gmail. Early adopters were quick to jump on board, and within 2 weeks Google+ reached 10M users.
Google continued to update Panda-impacted sites and data, and version 2.2 was officially acknowledged. Panda updates occurred separately from the main index and not in real-time, reminiscent of early Google Dance updates.
Google, Yahoo and Microsoft jointly announced support for a consolidated approach to structured data. They also created a number of new “schemas”, in an apparent bid to move toward even richer search results.
Initially dubbed “Panda 3.0”, Google appeared to roll out yet another round of changes. These changes weren’t discussed in detail by Google and seemed to be relatively minor.
Google rolled out the Panda update to all English queries worldwide (not limited to English-speaking countries). New signals were also integrated, including data about sites users blocked via the SERPs directly or the Chrome browser.
Responding to competition by major social sites, including Facebook and Twitter, Google launched the +1 button (directly next to results links). Clicking [+1] allowed users to influence search results within their social circle, across both organic and paid results.
A major algorithm update hit sites hard, affecting up to 12% of search results (a number that came directly from Google). Panda seemed to crack down on thin content, content farms, sites with high ad-to-content ratios, and a number of other quality issues. Panda rolled out over at least a couple of months, hitting Europe in April 2011.
In response to high-profile spam cases, Google rolled out an update to help better sort out content attribution and stop scrapers. According to Matt Cutts, this affected about 2% of queries. It was a clear precursor to the Panda updates.
In a rare turn of events, a public outing of shady SEO practices by Overstock.com resulted in a very public Google penalty. JCPenney was hit with a penalty in February for similar bad behavior. Both situations represented a shift in Google’s attitude and foreshadowed the Panda update.
After an expose in the New York Times about how e-commerce site DecorMyEyes was ranking based on negative reviews, Google made a rare move and reactively adjusted the algorithm to target sites using similar tactics.
Google and Bing confirmed that they use social signals in determining ranking, including data from Twitter and Facebook. Matt Cutts confirmed that this was a relatively new development for Google, although many SEOs had long suspected it would happen.
A magnifying glass icon appeared on Google search results, allowing search visitors to quickly view a preview of landing pages directly from SERPs. This signaled a renewed focus for Google on landing page quality, design, and usability.
Expanding on Google Suggest, Google Instant launched, displaying search results as a query was being typed. SEOs everywhere nearly spontaneously combusted, only to realize that the impact was ultimately fairly small.
Although not a traditional algorithm update, Google started allowing the same domain to appear multiple times on a SERP. Previously, domains were limited to 1-2 listings, or 1 listing with indented results.
After months of testing, Google finished rolling out the Caffeine infrastructure. Caffeine not only boosted Google’s raw speed, but integrated crawling and indexation much more tightly, resulting in (according to Google) a 50% fresher index.
In late April and early May, webmasters noticed significant drops in their long-tail traffic. Matt Cutts later confirmed that May Day was an algorithm change impacting the long-tail. Sites with large-scale thin content seemed to be hit especially hard, foreshadowing the Panda update.
Although “Places” pages were rolled out in September of 2009, they were originally only a part of Google Maps. The official launch of Google Places re-branded the Local Business Center, integrated Places pages more closely with local search results, and added a number of features, including new local advertising options.
This time, real-time search was for real- Twitter feeds, Google News, newly indexed content, and a number of other sources were integrated into a real-time feed on some SERPs. Sources continued to expand over time, including social media.
Google released a preview of a massive infrastructure change, designed to speed crawling, expand the index, and integrate indexation and ranking in nearly real-time. The timeline spanned months, with the final rollout starting in the US in early 2010 and lasting until the summer.
SEOs reported a major update that seemed to strongly favor big brands. Matt Cutts called Vince a “minor change”, but others felt it had profound, long-term implications.
Google, Microsoft, and Yahoo jointly announced support for the Canonical Tag, allowing webmasters to send canonicalization signals to search bots without impacting human visitors.
In a major change to their logo-and-a-box home-page Google introduced Suggest, displaying suggested searches in a dropdown below the search box as visitors typed their queries. Suggest would later go on to power Google Instant.
A large-scale shuffle seemed to occur at the end of March and into early April, but the specifics were unclear. Some suspected Google was pushing its own internal properties, including Google Books, but the evidence of that was limited.
In honor of Vanessa Fox leaving Google, the “Buffy” update was christened. No one was quite sure what happened, and Matt Cutts suggested that Buffy was just an accumulation of smaller changes.
While not your typical algorithm update, Google integrated traditional search results with News, Video, Images, Local, and other verticals, dramatically changing their format. The old 10-listing SERP was officially dead. Long live the old 10-listing SERP.
Throughout 2006, Google seemed to make changes to the supplemental index and how filtered pages were treated. They claimed in late 2006 that supplemental was not a penalty (even if it sometimes felt that way).
Technically, Big Daddy was an infrastructure update (like the more recent “Caffeine”), and it rolled out over a few months, wrapping up in March of 2006. Big Daddy changed the way Google handled URL canonicalization, redirects (301/302) and other technical issues.
After launching the Local Business Center in March 2005 and encouraging businesses to update their information, Google merged its Maps data into the LBC, in a move that would eventually drive a number of changes in local SEO.
Google released a series of updates, mostly targeted at low-quality links, including reciprocal links, link farms, and paid links. Jagger rolled out in at least 3 stages, from roughly September to November of 2005, with the greatest impact occurring in October.
Also called the “False” update ? webmasters saw changes (probably ongoing), but Google claimed no major algorithm update occurred. Matt Cutts wrote a blog post explaining that Google updated (at the time) index data daily but Toolbar PR and some other metrics only once every 3 months.
Google allowed webmasters to submit XML sitemaps via Webmaster Tools, bypassing traditional HTML sitemaps, and giving SEOs direct (albeit minor) influence over crawling and indexation.
Unlike previous attempts at personalization, which required custom settings and profiles, the 2005 roll-out of personalized search tapped directly into users? search histories to automatically adjust results. Although the impact was small at first, Google would go on to use search history for many applications.
“GoogleGuy” (likely Matt Cutts) announced that Google was rolling out “something like 3.5 changes in search quality.” No one was sure what 0.5 of a change was, but Webmaster World members speculated that Bourbon changed how duplicate content and non-canonical (www vs. non-www) URLs were treated.
Webmasters witnessed ranking changes, but the specifics of the update were unclear. Some thought Allegra affected the “sandbox” while others believed that LSI had been tweaked. Additionally, some speculated that Google was beginning to penalize suspicious links.
To combat spam and control outbound link quality, Google, Yahoo, and Microsoft collectively introduce the “nofollow” attribute. Nofollow helps clean up unvouched for links, including spammy blog comments. While not a traditional algorithm update, this change gradually has a significant impact on the link graph.
Although obviously not an algorithm update, a major event in Google’s history – Google sold 19M shares, raised $1.67B in capital, and set their market value at over $20B. By January 2005, Google share prices more than doubled.
Google rolled out a variety of changes, including a massive index expansion, Latent Semantic Indexing (LSI), increased attention to anchor text relevance, and the concept of link “neighborhoods.” LSI expanded Google’s ability to understand synonyms and took keyword analysis to the next level.
What Florida missed, Austin came in to clean up. Google continued to crack-down on deceptive on-page tactics, including invisible text and META-tag stuffing. Some speculated that Google put the “Hilltop” algorithm into play and began to take page relevance seriously.
This was the update that put updates (and probably the SEO industry) on the map. Many sites lost ranking, and business owners were furious. Florida sounded the death knell for low-value late 90s SEO tactics, like keyword stuffing, and made the game a whole lot more interesting.
In order to index more documents without sacrificing performance, Google split off some results into the “supplemental” index. The perils of having results go supplemental became a hotly debated SEO topic, until the index was later reintegrated.
The monthly “Google Dance” finally came to an end with the “Fritz” update. Instead of completely overhauling the index on a roughly monthly basis, Google switched to an incremental approach. The index was now changing daily.
This marked the last of the regular monthly Google updates, as a more continuous update process began to emerge. The “Google Dance” was replaced with “Everflux”. Esmerelda probably heralded some major infrastructure changes at Google.
While many changes were observed in May, the exact nature of Dominic was unclear. Google bots “Freshbot” and “Deepcrawler” scoured the web, and many sites reported bounces. The way Google counted or reported backlinks seemed to change dramatically.
Google cracked down on some basic link-quality issues, such as massive linking from co-owned domains. Cassandra also came down hard on hidden text and hidden links.
Announced at SES Boston, this was the first named Google update. Originally, Google aimed at a major monthly update, so the first few updates were a combination of algorithm changes and major index refreshes (the so-called “Google Dance”). As updates became more frequent, the monthly idea quickly died.
2002 Updates
1st Documented Update — September 2002
Before “Boston” (the first named update), there was a major shuffle in the Fall of 2002. The details are unclear, but this appeared to be more than the monthly Google Dance and PageRank update. As one webmaster said of Google: “they move the toilet mid stream”.
Guaranteeing SEO arguments for years to come, Google launched their browser toolbar, and with it, Toolbar PageRank (TBPR). As soon as webmasters started watching TBPR, the Google Dance began.
After executing “The Skyscraper Technique“, the number of backlinks to that page shot up like a rocket:
More importantly, organic search traffic to my entire site — not just that post — doubled in just 14 days:
As a nice bonus, that single post has driven more than 300,000 referral visitors to my site so far.
The best part?
You can do the same thing for your site…even if you don’t have a Fortune 500 marketing budget or connections with influential bloggers.
The 3-Steps to Using “The Skyscraper Technique” To Get Quality Links and Targeted Traffic
Like I mentioned in the video above, here are the 3-steps that make up The Skyscraper Technique:
Step 1: Find link-worthy content
Step 2: Make something even better
Step 3: Reach out to the right people
Here’s why this technique works so well (and what it has to do with a skyscraper):
Have you ever walked by a really tall building and said to yourself:
“Wow, that’s amazing! I wonder how big the 8th tallest building in the world is.”
Of course not.
It’s human nature to be attracted to the best.
And what you’re doing here is finding the tallest “skyscraper” in your space…and slapping 20 stories to the top of it.
All of a sudden YOU have the content that everyone wants to talk about (and link to).
Now: The Skyscraper Technique is just one of many strategies that I use to land first page Google rankings. I reveal the others in my premium business training course, SEO That Works.
Step #1: Find Proven Linkable Assets
A linkable asset is the foundation of any successful link-focused content marketing campaign (including this one).
I’m not sure who coined the phrase “Linkable Asset”, but it’s the perfect description of what you want to create: a high-value page that you can leverage for links over and over again.
Keep in mind that linkable asset is not “12 Things Spider Man Taught Me About Social Media Marketing” link bait nonsense.
It’s content so awesome, so incredible, and so useful that people can’t help but login to their WordPress dashboard and add a link to your site.
But how do you know if your linkable asset is going to be a huge success…or a total flop?
That’s easy: find content that’s already generated a ton of links.
Step #2: Make Something Even Better
Your next step is to take what’s out there and blow it out of the water.
Here’s how you can take existing content to the next level:
Make It Longer
In some cases, publishing an article that’s simply longer or includes more items
will do the trick.
If you find a link magnet with a title like “50 Healthy Snack Ideas”, publish a list of 150 (or even 500).
In my case, I decided to list all 200 ranking factors…or die trying.
The first 50 were a breeze. 50-100 were really hard. 100-150 were really, really hard. And 150-200 were damn near impossible.
It took 10 gallons of coffee and 20-hours of sitting in front of my laptop (don’t worry, I took bathroom breaks)…
…but in the end, I had something that was clearly better than anything else out there.
More Up-To-Date
If you can take an out of date piece of content and spruce it up, you’ve got yourself a winner.
For example, most of the other ranking factor lists were sorely outdated and lacked important ranking factors, like social signals:
If you find something with old information, create something that covers many of the same points…but update it with cutting-edge content.
Better Designed
Sometimes, a visually stunning piece of content can generate a lot more links and social shares than something similar on an ugly page.
This guide is a curated list of links to other internet marketing sites.
And the page has generated a lot of buzz because it’s beautifully designed.
For my guide, I added a nice banner at the top:
More Thorough
Most lists posts are just a bland list of bullet points without any meaty content that people can actually use.
But if you add a bit of depth for each item on your list, you have yourself a list post that’s MUCH more valuable.
In my case I noticed that the other ranking factor lists lacked references and detail Important Note: I recommend that you beat the existing content on every level: length, design, current information etc.
This will make it objectively clear that YOU have the better piece of content.
Which is really important when you start getting the word out…
Step #3: Reach Out to The Right People
Email outreach is the linchpin of the Skyscraper Technique.
It’s similar to straight up link begging, but with a VERY important twist.
Instead of emailing random people, you’re reaching out to site owners that have already linked out to similar content.
When you qualify prospects like this, you know that:
1. They run a site in your niche.
2. They’re interested in your topic.
3. They’ve already linked to an article on that topic.
Now it’s just a matter of giving them a friendly heads up about your clearly superior content.
Here’s how to do it:
1. Use ahrefs.com to export all of the links pointing to your competitor’s content into a spreadsheet. Tools like Majestic SEO and Open Site Explorer will also work.
2. Weed out referring pages that don’t make sense to contact (forums, article directories etc.). In my case, after cleaning up the list, I had 160 very solid prospects to reach out to.
3. I emailed all 160 of them using this template:
Even I was shocked at the overwhelmingly positive response:
Out of 160 emails I landed 17 links: an 11% success rate.
Considering that these were cold emails that asked for a link in the first email, an 11% success rate is pretty amazing.
You may be thinking, “17 links, that’s it?”.
But remember it’s about quality, not quantity.
There were a lot of gems in that group of 17 links.
Besides, just look at the meteoric rise in organic traffic that those 17 links got me (in a very short time period, no less).
Obviously there were a few links to that page that came organically, but some of the best were from The Skyscraper Technique.
You probably already know that Google uses about 200 ranking factors in their algorithm…
But what the heck are they?
Well today you’re in for a treat because I’ve put together a complete list.
Some are proven.
Some are controversial.
Others are SEO nerd speculation.
But they’re all here.
Domain Factors
1. Domain Age: In this video, Matt Cutts states that:
“The difference between a domain that’s six months old versus one year old is really not that big at all.”.
In other words, they do use domain age…but it’s not very important.
2. Keyword Appears in Top Level Domain: Doesn’t give the boost that it used to, but having your keyword in the domain still acts as a relevancy signal. After all, they still bold keywords that appear in a domain name.
3. Keyword As First Word in Domain: A domain that starts with their target keyword has an edge over sites that either don’t have the keyword in their domain or have the keyword in the middle or end of their domain.
4. Domain registration length: A Google patent states:
“Valuable (legitimate) domains are often paid for several years in advance, while doorway (illegitimate) domains rarely are used for more than a year. Therefore, the date when a domain expires in the future can be used as a factor in predicting the legitimacy of a domain”.
5. Keyword in Subdomain Name: Moz’s 2011 panel agreed that a keyword appearing in the subdomain can boost rankings:
6. Domain History: A site with volatile ownership (via whois) or several drops may tell Google to “reset” the site’s history, negating links pointing to the domain.
7. Exact Match Domain: EMDs may still give you an edge…if it’s a quality site. But if the EMD happens to be a low-quality site, it’s vulnerable to the EMD update:
8. Public vs. Private WhoIs: Private WhoIs information may be a sign of “something to hide”. Matt Cutts is quoted as stating at Pubcon 2006:
“…When I checked the whois on them, they all had “whois privacy protection service” on them. That’s relatively unusual. …Having whois privacy turned on isn’t automatically bad, but once you get several of these factors all together, you’re often talking about a very different type of webmaster than the fellow who just has a single site or so.”
9. Penalized WhoIs Owner: If Google identifies a particular person as a spammer it makes sense that they would scrutinize other sites owned by that person.
10. Country TLD extension: Having a Country Code Top Level Domain (.cn, .pt, .ca) helps the site rank for that particular country…but limits the site’s ability to rank globally.
Page-Level Factors
11. Keyword in Title Tag: The title tag is a webpage’s second most important piece of content (besides the content of the page) and therefore sends a strong on-page SEO signal.
12. Title Tag Starts with Keyword: According to Moz data, title tags that starts with a keyword tend to perform better than title tags with the keyword towards the end of the tag:
13. Keyword in Description Tag: Another relevancy signal. Not especially important now, but still makes a difference.
14. Keyword Appears in H1 Tag: H1 tags are a “second title tag” that sends another relevancy signal to Google, according to results from this correlation study:
15. Keyword is Most Frequently Used Phrase in Document: Having a keyword appear more than any other likely acts as a relevancy signal.
16. Content Length: Content with more words can cover a wider breadth and are likely preferred to shorter superficial articles. SERPIQ found that content length correlated with SERP position:17. Keyword Density: Although not as important as it once was, keyword density is still something Google uses to determine the topic of a webpage. But going overboard can hurt you.
18. Latent Semantic Indexing Keywords in Content(LSI): LSI keywords help search engines extract meaning from words with more than one meaning (Apple the computer company vs. the fruit). The presence/absence of LSI probably also acts as a content quality signal.
19. LSI Keywords in Title and Description Tags: As with webpage content, LSI keywords in page meta tags probably help Google discern between synonyms. May also act as a relevancy signal.
20. Page Loading Speed via HTML: Both Google and Bing use page loading speed as a ranking factor. Search engine spiders can estimate your site speed fairly accurately based on a page’s code and filesize.
21. Duplicate Content: Identical content on the same site (even slightly modified) can negatively influence a site’s search engine visibility.
22. Rel=Canonical: When used properly, use of this tag may prevent Google from considering pages duplicate content.
23. Page Loading Speed via Chrome: Google may also use Chrome user data to get a better handle on a page’s loading time as this takes into account server speed, CDN usage and other non HTML-related site speed signals.
24. Image Optimization: Images on-page send search engines important relevancy signals through their file name, alt text, title, description and caption.
25. Recency of Content Updates: Google Caffeine update favors recently updated content, especially for time-sensitive searches. Highlighting this factor’s importance, Google shows the date of a page’s last update for certain pages:
26. Magnitude of Content Updates: The significance of edits and changes is also a freshness factor. Adding or removing entire sections is a more significant update than switching around the order of a few words.
27. Historical Updates Page Updates: How often has the page been updated over time? Daily, weekly, every 5-years? Frequency of page updates also play a role in freshness.
28. Keyword Prominence: Having a keyword appear in the first 100-words of a page’s content appears to be a significant relevancy signal.
29. Keyword in H2, H3 Tags: Having your keyword appear as a subheading in H2 or H3 format may be another weak relevancy signal. Moz’s panel agrees:
30. Keyword Word Order: An exact match of a searcher’s keyword in a page’s content will generally rank better than the same keyword phrase in a different order. For example: consider a search for: “cat shaving techniques”. A page optimized for the phrase “cat shaving techniques” will rank better than a page optimized for “techniques for shaving a cat”. This is a good illustration of why keyword research is really, really important.
31. Outbound Link Quality: Many SEOs think that linking out to authority sites helps send trust signals to Google.
32. Outbound Link Theme: According to Moz, search engines may use the content of the pages you link to as a relevancy signal. For example, if you have a page about cars that links to movie-related pages, this may tell Google that your page is about the movie Cars, not the automobile.
33. Grammar and Spelling: Proper grammar and spelling is a quality signal, although Cutts gave mixed messages in 2011 on whether or not this was important.
34. Syndicated Content: Is the content on the page original? If it’s scraped or copied from an indexed page it won’t rank as well as the original or end up in their Supplemental Index.
35. Helpful Supplementary Content: According to a now-public Google Rater Guidelines Document, helpful supplementary content is an indicator of a page’s quality (and therefore, Google ranking). Examples include currency converters, loan interest calculators and interactive recipes.
36. Number of Outbound Links: Too many dofollow OBLs may “leak” PageRank, which can hurt that page’s rankings.
37. Multimedia: Images, videos and other multimedia elements may act as a content quality signal.
38. Number of Internal Links Pointing to Page: The number of internal links to a page indicates its importance relative to other pages on the site.
39. Quality of Internal Links Pointing to Page: Internal links from authoritative pages on domain have a stronger effect than pages with no or low PR.
40. Broken Links: Having too many broken links on a page may be a sign of a neglected or abandoned site. The Google Rater Guidelines Document uses broken links as one was to assess a homepage’s quality.
41. Reading Level: There’s no doubt that Google estimates the reading level of webpages. In fact, Google used to give you reading level stats:
But what they do with that information is up for debate. Some say that a basic reading level will help you rank better because it will appeal to the masses. But others associate a basic reading level with content mills like Ezine Articles.
42. Affiliate Links: Affiliate links themselves probably won’t hurt your rankings. But if you have too many, Google’s algorithm may pay closer attention to other quality signals to make sure you’re not a “thin affiliate site”.
43. HTML errors/W3C validation: Lots of HTML errors or sloppy coding may be a sign of a poor quality site. While controversial, many in SEO think that WC3 validation is a weak quality signal.
44. Page Host’s Domain Authority: All things being equal, a page on an authoritative domain will rank higher than a page on a domain with less authority.
45. Page’s PageRank: Not perfectly correlated. But in general higher PR pages tend to rank better than low PR pages.
46. URL Length:Search Engine Journal notes that excessively long URLs may hurt search visibility.
47. URL Path: A page closer to the homepage may get a slight authority boost.
48. Human Editors: Although never confirmed, Google has filed a patent for a system that allows human editors to influence the SERPs.
49. Page Category: The category the page appears on is a relevancy signal. A page that’s part of a closely related category should get a relevancy boost compared to a page that’s filed under an unrelated or less related category.
50. WordPress Tags: Tags are WordPress-specific relevancy signal. According to Yoast.com:
“The only way it improves your SEO is by relating one piece of content to another, and more specifically a group of posts to each other”
51. Keyword in URL: Another important relevancy signal.
52. URL String: The categories in the URL string are read by Google and may provide a thematic signal to what a page is about:
53. References and Sources: Citing references and sources, like research papers do, may be a sign of quality. The Google Quality Guidelines states that reviewers should keep an eye out for sources when looking at certain pages: “This is a topic where expertise and/or authoritative sources are important…”. However, Google has denied that they use external links as a ranking signal.
54. Bullets and Numbered Lists: Bullets and numbered lists help break up your content for readers, making them more user friendly. Google likely agrees and may prefer content with bullets and numbers.
55. Priority of Page in Sitemap: The priority a page is given via the sitemap.xml file may influence ranking.
56. Too Many Outbound Links: Straight from the aforementioned Quality rater document:
“Some pages have way, way too many links, obscuring the page and distracting from the Main Content”
57. Quantity of Other Keywords Page Ranks For: If the page ranks for several other keywords it may give Google an internal sign of quality.
58. Page Age: Although Google prefers fresh content, an older page that’s regularly updated may outperform a newer page.
59. User Friendly Layout: Citing the Google Quality Guidelines Document yet again:
“The page layout on highest quality pages makes the Main Content immediately visible”
60. Parked Domains: A Google update in December of 2011 decreased search visibility of parked domains.
62. Content Provides Value and Unique Insights: Google has stated that they’re on the hunt for sites that don’t bring anything new or useful to the table, especially thin affiliate sites.
63. Contact Us Page: The aforementioned Google Quality Document states that they prefer sites with an “appropriate amount of contact information”. Supposed bonus if your contact information matches your whois info.
64. Domain Trust/TrustRank: Site trust — measured by how many links away your site is from highly-trusted seed sites — is a massively important ranking factor. You can read more about TrustRank here.
65. Site Architecture: A well put-together site architecture (especially a silo structure) helps Google thematically organize your content.
66. Site Updates: How often a site is updated — and especially when new content is added to the site — is a site-wide freshness factor.
67. Number of Pages: The number of pages a site has is a weak sign of authority. At the very least a large site helps distinguish it from thin affiliate sites.
68. Presence of Sitemap: A sitemap helps search engines index your pages easier and more thoroughly, improving visibility.
69. Site Uptime: Lots of downtime from site maintenance or server issues may hurt your ranking (and can even result in deindexing if not corrected).
70. Server Location: Server location may influence where your site ranks in different geographical regions. Especially important for geo-specific searches.
75. Mobile Optimized: Google’s official stance on mobile is to create a responsive site. It’s likely that responsive sites get an edge in searches from a mobile device. In fact, they now add “Mobile friendly” tags to sites that display well on mobile devices. Google also started penalizing sites in Mobile search that aren’t mobile friendly
76. YouTube: There’s no doubt that YouTube videos are given preferential treatment in the SERPs (probably because Google owns it ):
77. Site Usability: A site that’s difficult to use or to navigate can hurt ranking by reducing time on site, pages viewed and bounce rate. This may be an independent algorithmic factor gleaned from massive amounts of user data.
78. Use of Google Analytics and Google Webmaster Tools: Some think that having these two programs installed on your site can improve your page’s indexing. They may also directly influence rank by giving Google more data to work with (ie. more accurate bounce rate, whether or not you get referral traffic from your backlinks etc.).
79. User reviews/Site reputation: A site’s on review sites like Yelp.com and RipOffReport.com likely play an important role in the algorithm. Google even posted a rarely candid outline of their approach to user reviews after an eyeglass site was caught ripping off customers in an effort to get backlinks.
Backlink Factors
80. Linking Domain Age: Backlinks from aged domains may be more powerful than new domains.
81. # of Linking Root Domains: The number of referring domains is one of the most important ranking factors in Google’s algorithm, as you can see from this chart from Moz (bottom axis is SERP position):
82. # of Links from Separate C-Class IPs: Links from separate class-c IP addresses suggest a wider breadth of sites linking to you.
83. # of Linking Pages: The total number of linking pages — even if some are on the same domain — is a ranking factor.
84. Alt Tag (for Image Links): Alt text is an image’s version of anchor text.
85. Links from .edu or .gov Domains: Matt Cutts has stated that TLD doesn’t factor into a site’s importance. However, that doesn’t stop SEOs from thinking that there’s a special place in the algo for .gov and .edu TLDs.
86. Authority of Linking Page: The authority (PageRank) of the referring page is an extremely important ranking factor.
87. Authority of Linking Domain: The referring domain’s authority may play an independent role in a link’s importance (ie. a PR2 page link from a site with a homepage PR3 may be worth less than a PR2 page link from PR8 Yale.edu).
88. Links From Competitors: Links from other pages ranking in the same SERP may be more valuable for a page’s rank for that particular keyword.
89. Social Shares of Referring Page: The amount of page-level social shares may influence the link’s value.
90. Links from Bad Neighborhoods: Links from “bad neighborhoods” may hurt your site.
91. Guest Posts: Although guest posting can be part of a white hat SEO campaign, links coming from guest posts — especially in an author bio area — may not be as valuable as a contextual link on the same page.
92. Links to Homepage Domain that Page Sits On: Links to a referring page’s homepage may play special importance in evaluating a site’s — and therefore a link’s — weight.
93. Nofollow Links: One of the most controversial topics in SEO. Google’s official word on the matter is:
“In general, we don’t follow them.”
Which suggests that they do…at least in certain cases. Having a certain % of nofollow links may also indicate a natural vs. unnatural link profile.
94. Diversity of Link Types: Having an unnaturally large percentage of your links come from a single source (ie. forum profiles, blog comments) may be a sign of webspam. On the other hand, links from diverse sources is a sign of a natural link profile.
95. “Sponsored Links” Or Other Words Around Link: Words like “sponsors”, “link partners” and “sponsored links” may decrease a link’s value.
96. Contextual Links: Links embedded inside a page’s content are considered more powerful than links on an empty page or found elsewhere on the page.
97. Excessive 301 Redirects to Page: Links coming from 301 redirects dilute some (or even all) PR, according to a Webmaster Help Video.
98. Backlink Anchor Text: As noted in this description of Google’s original algorithm:
“First, anchors often provide more accurate descriptions of web pages than the pages themselves.”
Obviously, anchor text is less important than before (and likely a webspam signal). But it still sends a strong relevancy signal in small doses.
99. Internal Link Anchor Text: Internal link anchor text is another relevancy signal, although probably weighed differently than backlink anchor text.
100. Link Title Attribution: The link title (the text that appears when you hover over a link) is also used as a weak relevancy signals.
101. Country TLD of Referring Domain: Getting links from country-specific top level domain extensions (.de, .cn, .co.uk) may help you rank better in that country.
102. Link Location In Content: Links in the beginning of a piece of content carry slightly more weight than links placed at the end of the content.
103. Link Location on Page: Where a link appears on a page is important. Generally, links embedded in a page’s content are more powerful than links in the footer or sidebar area.
104. Linking Domain Relevancy: A link from site in a similar niche is significantly more powerful than a link from a completely unrelated site. That’s why any effective SEO strategy today focuses on obtaining relevant links.
105. Page Level Relevancy:The Hilltop Algorithm states that link from a page that’s closely tied to page’s content is more powerful than a link from an unrelated page.
106. Text Around Link Sentiment: Google has probably figured out whether or not a link to your site is a recommendation or part of a negative review. Links with positive sentiments around them likely carry more weight.
107. Keyword in Title: Google gives extra love to links on pages that contain your page’s keyword in the title (“Experts linking to experts”.)
108. Positive Link Velocity: A site with positive link velocity usually gets a SERP boost.
109. Negative Link Velocity: Negative link velocity can significantly reduce rankings as it’s a signal of decreasing popularity.
110. Links from “Hub” Pages:Aaron Wall claims that getting links from pages that are considered top resources (or hubs) on a certain topic are given special treatment.
111. Link from Authority Sites: A link from a site considered an “authority site” likely pass more juice than a link from a small, microniche site.
112. Linked to as Wikipedia Source: Although the links are nofollow, many think that getting a link from Wikipedia gives you a little added trust and authority in the eyes of search engines.
114. Backlink Age: According to a Google patent, older links have more ranking power than newly minted backlinks.
115. Links from Real Sites vs. Splogs: Due to the proliferation of blog networks, Google probably gives more weight to links coming from “real sites” than from fake blogs. They likely use brand and user-interaction signals to distinguish between the two.
116. Natural Link Profile: A site with a “natural” link profile is going to rank highly and be more durable to updates.
117. Reciprocal Links: Google’s Link Schemes page lists “Excessive link exchanging” as a link scheme to avoid.
118. User Generated Content Links: Google is able to identify links generated from UGC vs. the actual site owner. For example, they know that a link from the official WordPress.com blog at en.blog.wordpress.com is very different than a link from besttoasterreviews.wordpress.com.
119. Links from 301: Links from 301 redirects may lose a little bit of juice compared to a direct link. However, Matt Cutts says that a 301 is similar to a direct link.
120. Schema.org Microformats: Pages that support microformats may rank above pages without it. This may be a direct boost or the fact that pages with microformatting have a higher SERP CTR:
121. DMOZ Listed: Many believe that Google gives DMOZ listed sites a little extra trust.
122. TrustRank of Linking Site: The trustworthiness of the site linking to you determines how much “TrustRank” gets passed onto you.
123. Number of Outbound Links on Page: PageRank is finite. A link on a page with hundreds of OBLs passes less PR than a page with only a few OBLs.
124. Forum Profile Links: Because of industrial-level spamming, Google may significantly devalue links from forum profiles.
125. Word Count of Linking Content: A link from a 1000-word post is more valuable than a link inside of a 25-word snippet.
126. Quality of Linking Content: Links from poorly written or spun content don’t pass as much value as links from well-written, multimedia-enhanced content.
127. Sitewide Links: Matt Cutts has confirmed that sitewide links are “compressed” to count as a single link.
Video tutorial
My Go-To Link Building Strategy
User Interaction
128. Organic Click Through Rate for a Keyword: Pages that get clicked more in CTR may get a SERP boost for that particular keyword.
129. Organic CTR for All Keywords: A page’s (or site’s) organic CTR for all keywords is ranks for may be a human-based, user interaction signal.
130. Bounce Rate: Not everyone in SEO agrees bounce rate matters, but it may be a way of Google to use their users as quality testers (pages where people quickly bounce is probably not very good).
131. Direct Traffic: It’s confirmed that Google uses data from Google Chrome to determine whether or not people visit a site (and how often). Sites with lots of direct traffic are likely higher quality than sites that get very little direct traffic.
132. Repeat Traffic: They may also look at whether or not users go back to a page or site after visiting. Sites with repeat visitors may get a Google ranking boost.
133. BlockedSites: Google has discontinued this feature in Chrome. However, Panda used this feature as a quality signal.
135. Google Toolbar Data: Search Engine Watch’s Danny Goodwin reports that Google uses toolbar data as a ranking signal. However, besides page loading speed and malware, it’s not known what kind of data they glean from the toolbar.
136. Number of Comments: Pages with lots of comments may be a signal of user-interaction and quality.
137. Dwell Time: Google pays very close attention to “dwell time”: how long people spend on your page when coming from a Google search. This is also sometimes referred to as “long clicks vs short clicks”. If people spend a lot of time on your site, that may be used as a quality signal.
Video tutorial
How to Reduce Your Bounce Rate in 5 Minutes (Or Less)
Special Algorithm Rules
138. Query Deserves Freshness: Google gives newer pages a boost for certain searches.
139. Query Deserves Diversity: Google may add diversity to a SERP for ambiguous keywords, such as “Ted”, “WWF” or “ruby”.
140. User Browsing History: Sites that you frequently visit while signed into Google get a SERP bump for your searches.
141. User Search History: Search chain influence search results for later searches. For example, if you search for “reviews” then search for “toasters”, Google is more likely to show toaster review sites higher in the SERPs.
142. Geo Targeting: Google gives preference to sites with a local server IP and country-specific domain name extension.
143. Safe Search: Search results with curse words or adult content won’t appear for people with Safe Search turned on.
144. Google+ Circles: Google shows higher results for authors and sites that you’ve added to your Google Plus Circles
146. Domain Diversity: The so-called “Bigfoot Update” supposedly added more domains to each SERP page.
147. Transactional Searches: Google sometimes displays different results for shopping-related keywords, like flight searches.
148. Local Searches: Google often places Google+ Local results above the “normal” organic SERPs.
149. Google News Box: Certain keywords trigger a Google News box:
150. Big Brand Preference: After the Vince Update, Google began giving big brands a boost for certain short-tail searches.
151. Shopping Results: Google sometimes displays Google Shopping results in organic SERPs:
152. Image Results: Google elbows our organic listings for image results for searches commonly used on Google Image Search.
153. Easter Egg Results: Google has a dozen or so Easter Egg results. For example, when you search for “Atari Breakout” in Google image search, the search results turn into a playable game (!). Shout out to Victor Pan for this one.
155. Number of Tweets: Like links, the tweets a page has may influence its rank in Google.
156. Authority of Twitter Users Accounts: It’s likely that Tweets coming from aged, authority Twitter profiles with a ton of followers (like Justin Bieber) have more of an effect than tweets from new, low-influence accounts.
157. Number of Facebook Likes: Although Google can’t see most Facebook accounts, it’s likely they consider the number of Facebook likes a page receives as a weak ranking signal.
159. Authority of Facebook User Accounts: As with Twitter, Facebook shares and likes coming from popular Facebook pages may pass more weight.
160. Pinterest Pins: Pinterest is an insanely popular social media account with lots of public data. It’s probably that Google considers Pinterest Pins a social signal.
161. Votes on Social Sharing Sites: It’s possible that Google uses shares at sites like Reddit, Stumbleupon and Digg as another type of social signal.
162. Number of Google+1’s: Although Matt Cutts gone on the record as saying Google+ has “no direct effect” on rankings, it’s hard to believe that they’d ignore their own social network.
163. Authority of Google+ User Accounts: It’s logical that Google would weigh +1’s coming from authoritative accounts more than from accounts without many followers.
164. Known Authorship: In February 2013, Google CEO Eric Schmidt famously claimed:
“Within search results, information tied to verified online profiles will be ranked higher than content without such verification, which will result in most users naturally clicking on the top (verified) results.”
Although the Google+ authorship program has been shut down, it’s likely Google uses some form of authorship to determine influential content producers online (and give them a boost in rankings).
165. Social Signal Relevancy: Google probably uses relevancy information from the account sharing the content and the text surrounding the link.
166. Site Level Social Signals: Site-wide social signals may increase a site’s overall authority, which will increase search visibility for all of its pages.
Brand Signals
167. Brand Name Anchor Text: Branded anchor text is a simple — but strong — brand signal.
168. Branded Searches: It’s simple: people search for brands. If people search for your site in Google (ie. “Backlinko twitter”, Backlinko + “ranking factors”), Google likely takes this into consideration when determining a brand.
169. Site Has Facebook Page and Likes: Brands tend to have Facebook pages with lots of likes.
170. Site has Twitter Profile with Followers: Twitter profiles with a lot of followers signals a popular brand.
171. Official Linkedin Company Page: Most real businesses have company Linkedin pages.
172. Employees Listed at Linkedin: Rand Fishkin thinks that having Linkedin profiles that say they work for your company is a brand signal.
173. Legitimacy of Social Media Accounts: A social media account with 10,000 followers and 2 posts is probably interpreted a lot differently than another 10,000-follower strong account with lots of interaction.
174. Brand Mentions on News Sites: Really big brands get mentioned on Google News sites all the time. In fact, some brands even have their own Google News feed on the first page:
175. Co-Citations: Brands get mentioned without getting linked to. Google likely looks at non-hyperlinked brand mentions as a brand signal.
176. Number of RSS Subscribers: Considering that Google owns the popular Feedburner RSS service, it makes sense that they would look at RSS Subscriber data as a popularity/brand signal.
177. Brick and Mortar Location With Google+ Local Listing: Real businesses have offices. It’s possible that Google fishes for location-data to determine whether or not a site is a big brand.
178. Website is Tax Paying Business:Moz reports that Google may look at whether or not a site is associated with a tax-paying business.
On-Site WebSpam Factors
179. Panda Penalty: Sites with low-quality content (particularly content farms) are less visible in search after getting hit by a Panda penalty.
180. Links to Bad Neighborhoods: Linking out to “bad neighborhoods” — like pharmacy or payday loan sites — may hurt your search visibility.
181. Redirects: Sneaky redirects is a big no-no. If caught, it can get a site not just penalized, but de-indexed.
182. Popups or Distracting Ads: The official Google Rater Guidelines Document says that popups and distracting ads is a sign of a low-quality site.
183. Site Over-Optimization: Includes on-page factors like keyword stuffing, header tag stuffing, excessive keyword decoration.
184. Page Over-Optimization: Many people report that — unlike Panda — Penguin targets individual page (and even then just for certain keywords).
185. Ads Above the Fold: The “Page Layout Algorithm” penalizes sites with lots of ads (and not much content) above the fold.
186. Hiding Affiliate Links: Going too far when trying to hide affiliate links (especially with cloaking) can bring on a penalty.
187. Affiliate Sites: It’s no secret that Google isn’t the biggest fan of affiliates. And many think that sites that monetize with affiliate links are put under extra scrutiny.
188. Autogenerated Content: Google isn’t a big fan of autogenerated content. If they suspect that your site’s pumping out computer-generated content, it could result in a penalty or de-indexing.
189. Excess PageRank Sculpting: Going too far with PageRank sculpting — by nofollowing all outbound links or most internal links — may be a sign of gaming the system.
191. Meta Tag Spamming: Keyword stuffing can also happen in meta tags. If Google thinks you’re adding keywords to your meta tags to game the algo, they may hit your site with a penalty.
Off Page Webspam Factors
192. Unnatural Influx of Links: A sudden (and unnatural) influx of links is a sure-fire sign of phony links.
193. Penguin Penalty: Sites that were hit by Google Penguin are significantly less visible in search.
194. Link Profile with High % of Low Quality Links: Lots of links from sources commonly used by black hat SEOs (like blog comments and forum profiles) may be a sign of gaming the system.
195. Linking Domain Relevancy: The famous analysis by MicroSiteMasters.com found that sites with an unnaturally high amount of links from unrelated sites were more susceptible to Penguin.
196. Unnatural Links Warning: Google sent out thousands of “Google Webmaster Tools notice of detected unnatural links” messages. This usually precedes a ranking drop, although not 100% of the time.
197. Links from the Same Class C IP: Getting an unnatural amount of links from sites on the same server IP may be a sign of blog network link building.
198. “Poison” Anchor Text: Having “poison” anchor text (especially pharmacy keywords) pointed to your site may be a sign of spam or a hacked site. Either way, it can hurt your site’s ranking.
199. Manual Penalty: Google has been known to hand out manual penalties, like in the well-publicized Interflora fiasco.
200. Selling Links: Selling links can definitely impact toolbar PageRank and may hurt your search visibility.
201. Google Sandbox: New sites that get a sudden influx of links are sometimes put in the Google Sandbox, which temporarily limits search visibility.
202. Google Dance: The Google Dance can temporarily shake up rankings. According to a Google Patent, this may be a way for them to determine whether or not a site is trying to game the algorithm.
203. Disavow Tool: Use of the Disavow Tool may remove a manual or algorithmic penalty for sites that were the victims of negative SEO.
204. Reconsideration Request: A successful reconsideration request can lift a penalty.
205. Temporary Link Schemes: Google has (apparently) caught onto people that create — and quickly remove — spammy links. Also know as a temporary link scheme.
Google Fred Update Targets Ad Heavy, Low Value Content Sites
The Google Fred Update which we first spotted rolling out early morning on March 8th seems to be fairly big. After reviewing well over 70 sites that were hit by this update, 95% of them share two things in common. The sites all seem content driven, either blog formats or other content like sites and they all are pretty heavy on their ad placement. In fact, if I dare say, it looks like many (not all but many) of them were created with the sole purpose of generating AdSense or other ad income without necessarily benefiting the user.
The sites that got hit also saw 50% or higher drops in Google organic traffic overnight. I had them almost all of them share analytics screen shots with me to prove it. So this was a huge drop, in some cases up to 90% of their traffic was gone over night.
Here is one such screen shot of a site’s Google Analytics showing the drop. I’ve seen many that show 50% to 90% drops in their organic Google traffic:
Most of the webmasters that shared their URLs with me asked me not to share them publicly. But the truth is, there are plenty who shared their URLs publicly and I can use those as a reference below. Like I said, I will only share the public URLs here but I promise you, 95% of all the samples I received (both private and public), matched this overall theme – content sites that have many ads and are created for the purpose of generating revenue over solving a user problem.
In fact, some of these webmasters who reported huge recoveries told me they removed their ads. So, I am thinking Fred is not new but rather was turned up big time and more sites were hit by it than ever before. Maybe some of the previous unnamed updates, maybe the Phantom updates were smaller versions of this Fred update or maybe not – but to have sites recover big time, that means something previous hit them.
I should state – Google has not confirmed my theories or even that there was an update. But I am pushing them to give me some sort of statement.
Here are public sample sites that were potentially hit by Fred. Note, not all meet the “purpose is to generate ad revenue over help users” type of form, but I think many of them do.
“Siloing a website means grouping related pages together, either structurally or through linking, to establish the site’s keyword-based themes”
Silos are content taxonomies and linking structures that help to index your content, distribute link juice, add additional relevancy signals and push up rankings.
The infographic below demonstrates exactly how to set up both organizational silos andinternal linking silos for search engine optimization.
Silo’ in terms of SEO is referring to the internal linking structure of your website.
Original Link: https://www.quora.com/What-Is-SILO-In-SE

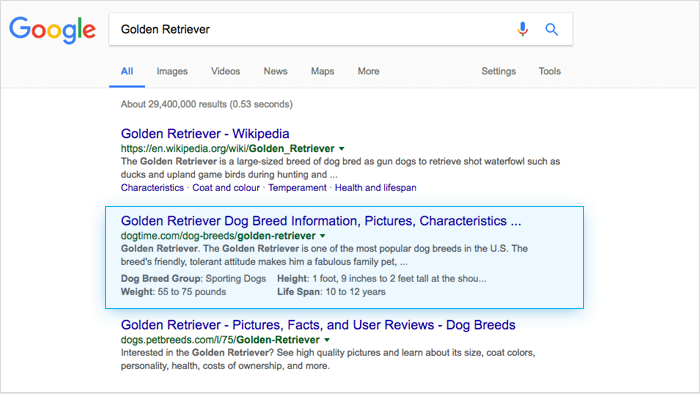




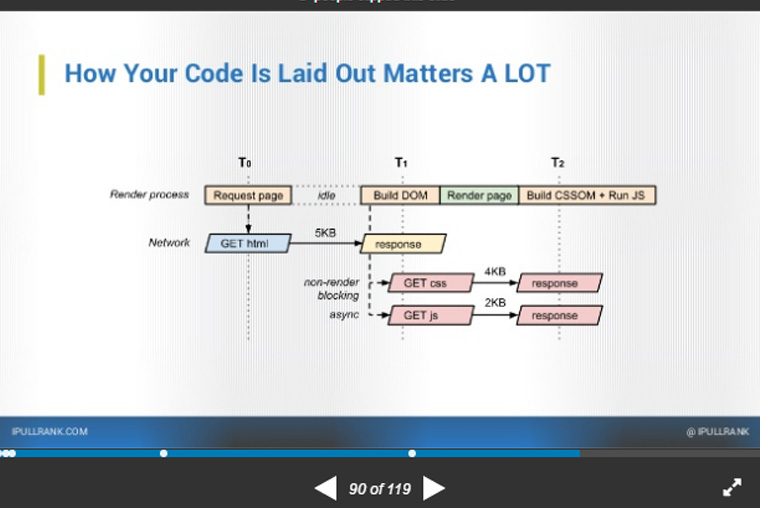



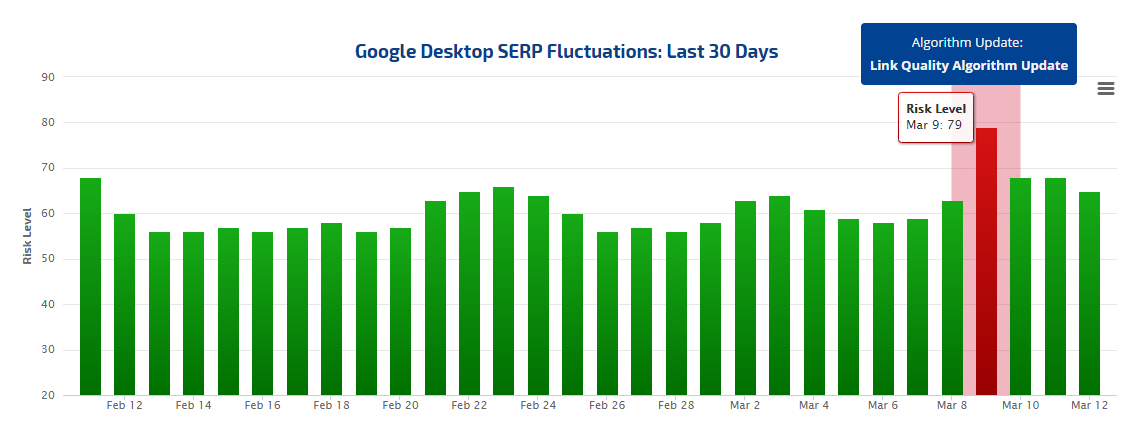
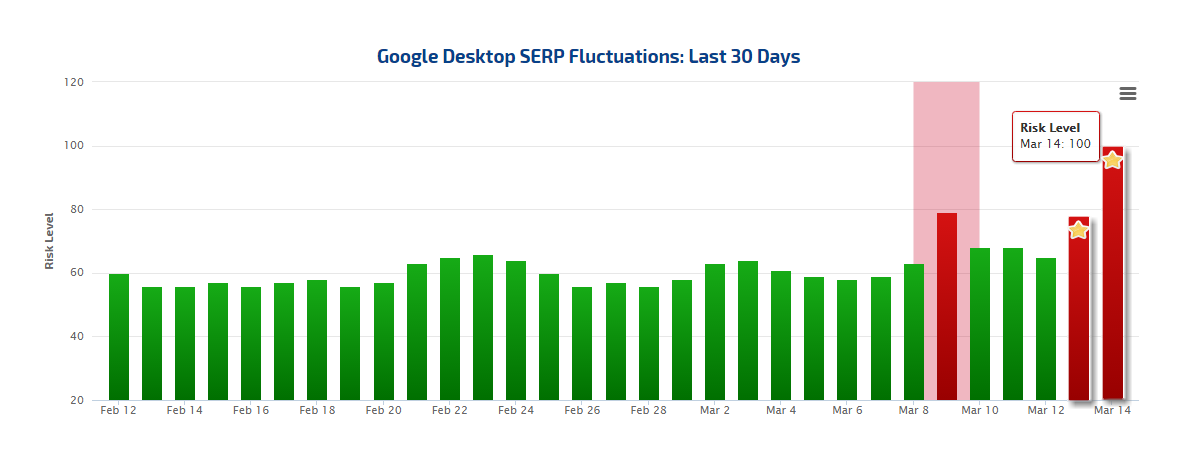
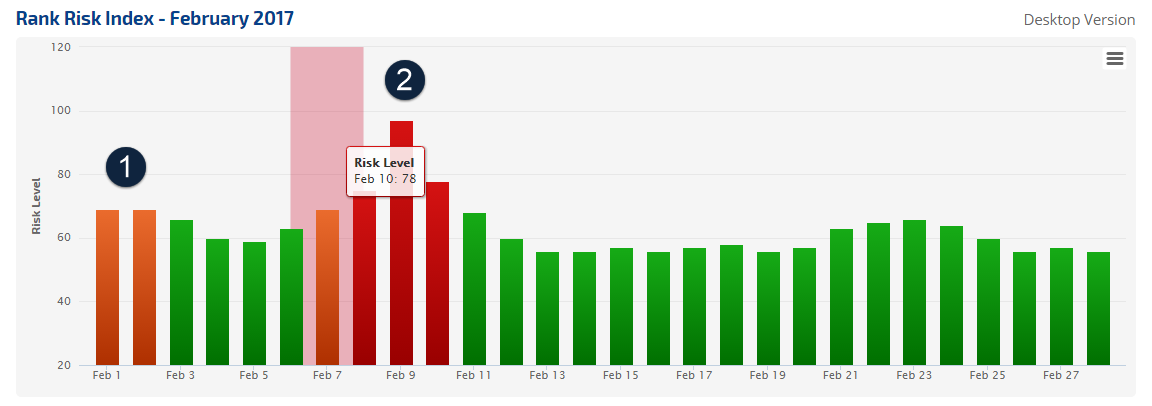









 6. Domain History: A site with volatile ownership (via whois) or several drops may tell Google to “reset” the site’s history, negating links pointing to the domain.
6. Domain History: A site with volatile ownership (via whois) or several drops may tell Google to “reset” the site’s history, negating links pointing to the domain.



 17. Keyword Density: Although not as important as it once was, keyword density is still something Google uses to determine the topic of a webpage. But going overboard can hurt you.
17. Keyword Density: Although not as important as it once was, keyword density is still something Google uses to determine the topic of a webpage. But going overboard can hurt you.